Théorème de Bayes
Le théorème de
Bayes est un résultat de base
en théorie des probabilités, issu des travaux
du révérend Thomas Bayes et retrouvé ensuite indépendamment par Laplace. Dans son unique article, Bayes
cherchait à déterminer ce que l’on appellerait actuellement la distribution a posteriori de la probabilité ![]() d’une loi binomiale.
Ses travaux ont été édités et présentés à titre posthume (1763) par son ami Richard Price dans Un
essai pour résoudre un problème dans la théorie des risques (An
Essay towards solving a Problem in the Doctrine of Chances).
Les résultats de Bayes ont été redécouverts et étendus par le mathématicien
français Laplace dans
un essai de 1774, lequel n’était
apparemment pas au fait du travail de Bayes.
d’une loi binomiale.
Ses travaux ont été édités et présentés à titre posthume (1763) par son ami Richard Price dans Un
essai pour résoudre un problème dans la théorie des risques (An
Essay towards solving a Problem in the Doctrine of Chances).
Les résultats de Bayes ont été redécouverts et étendus par le mathématicien
français Laplace dans
un essai de 1774, lequel n’était
apparemment pas au fait du travail de Bayes.
Le résultat principal (la Proposition 9 de l’essai) obtenu par
Bayes est le suivant : en considérant une distribution uniforme du paramètre
binomial p et une observation ![]() d'une loi binomiale
d'une loi binomiale ![]() , où m est donc le nombre d’issues positives
observées et n le nombre d’échecs observés, la
probabilité que p soit entre a et b sachant
, où m est donc le nombre d’issues positives
observées et n le nombre d’échecs observés, la
probabilité que p soit entre a et b sachant ![]() vaut :
vaut :
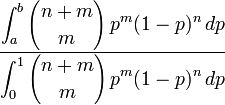
Ses résultats préliminaires, en particulier les propositions 3, 4
et 5 impliquent le résultat que l’on appelle théorème
de Bayes (énoncé plus bas)
mais il ne semble pas que Bayes se soit concentré ou ait insisté sur ce
résultat.
Ce qui est « bayésien » (au sens actuel du mot) dans la
Proposition 9, c’est que Bayes ait présenté cela comme une probabilité sur le
paramètre p. Cela revient
à dire qu’on peut déterminer, non seulement des probabilités à partir
d’observations issues d’une expérience, mais aussi les paramètres relatifs à
ces probabilités. C’est le même type de calcul analytique qui permet de
déterminer par inférence les deux. En revanche, si l’on s'en tient à une interprétation fréquentiste (en),
on est censé ne pas considérer de probabilité
de distribution du paramètre p et en conséquence, on ne peut
raisonner sur p qu’avec un raisonnement d’inférence non-probabiliste.
Le
théorème de Bayes en statistique [modifier]
Le théorème de Bayes est utilisé dans l’inférence statistique pour mettre à jour ou actualiser les
estimations d’une probabilité ou d’un paramètre quelconque, à partir des
observations et des lois de probabilité de ces observations. Il y a une version discrète et
une version continue du théorème.
·
L’école bayésienne utilise les probabilités comme moyen
de traduire numériquement un degré de connaissance (la théorie mathématique des
probabilités n’oblige en effet nullement à associer celles-ci à des fréquences,
qui n’en représentent qu’une application particulière résultant de la loi des
grands nombres). Dans cette optique, le théorème de Bayes peut s’appliquer à
toute proposition, quelle que soit la nature des variables et indépendamment de
toute considération ontologique.
·
L’école fréquentiste utilise les propriétés de long terme
de la loi des observations et ne considère pas de loi sur les paramètres,
inconnus mais fixés.
En théorie des probabilités, le théorème de Bayes énonce des probabilités conditionnelles : étant
donné deux évènements A et B,
le théorème de Bayes permet de déterminer la probabilité de A sachant B, si l’on connaît
les probabilités :
·
de A ;
·
de B ;
·
de B
sachant A.
Ce théorème élémentaire (originellement nommé « de
probabilité des causes ») a des applications considérables.
Pour aboutir au théorème de Bayes, on part d’une des définitions
de la probabilité conditionnelle :
![]()
en notant ![]() la
probabilité que A et B aient tous les deux lieu. En divisant
de part et d’autre par P(B),
on obtient :
la
probabilité que A et B aient tous les deux lieu. En divisant
de part et d’autre par P(B),
on obtient :
![]()
soit le théorème de Bayes.
Chaque terme du théorème de Bayes a une dénomination usuelle.
Le terme P(A)
est la probabilité a priori de A.
Elle est « antérieure » au sens qu’elle précède toute information sur B. P(A) est aussi appelée
la probabilité marginale de A.
Le terme P(A|B)
est appelée la probabilité a
posteriori de A sachant B (ou encore de A sous condition B) . Elle est
« postérieure », au sens qu’elle dépend directement deB. Le
terme P(B|A),
pour un B connu, est appelé la fonction de vraisemblance de A.
De même, le terme P(B)
est appelé la probabilité
marginale ou a priori de B.
Autres
écritures du théorème de Bayes [modifier]
On améliore parfois le théorème de Bayes en remarquant que
![]()
afin de réécrire le théorème ainsi :
![]()
où ![]() est le complémentaire de A.
Plus généralement, si {Ai} est une partition de l’ensemble des possibles,
est le complémentaire de A.
Plus généralement, si {Ai} est une partition de l’ensemble des possibles,
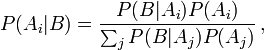
pour tout Ai de la partition.
Voyez aussi le théorème des probabilités totales.
La démarche d’I. J. Good [modifier]
I. J. Good reprend
une idée d’Alan Turing1 : les probabilités
deviennent plus faciles à manier si au lieu de raisonner sur une probabilité p,
on travaille sur une quantité construite de la façon suivante : ![]() ou
ou ![]()
qu’il nomme weight
of evidence, terme auquel on peut donner différentes traductions :
« poids de témoignage », « valeur de plausibilité », etc.
ou même, en utilisant cette fois-ci le mot français dans son acception
française... « évidence » ! Ce qui est intéressant à en retenir
est ceci :
·
Une evidence peut varier de moins l’infini à plus
l’infini.
·
On travaille souvent par commodité en décibels (dB),
10 log10 (p/(1-p))
·
L’observation d’un phénomène se traduit par une
variation d’evidence qui
constitue une translation d’evidence, la valeur de cette
translation ne dépendant pas des probabilités a priori de l’utilisateur. Une observation
apporte donc une information objective qui est la même pour tous les observateurs,
ce que la loi de Bayes ne montrait pas immédiatement.
Les statisticiens retrouvent de leur côté aussi cette formulation
avec la fonction logit introduite pour la régression logistique.
En calculs de fiabilité, où il faut manier des probabilités très
grandes (1-ε) et très petites (ε), travailler en termes d’evidences permet une visualisation bien plus
claire des classes de sécurité : une évidence de -70 dB correspond à une
probabilité de 10-7, etc. On peut également travailler en gardant en
toutes circonstances le même nombre de décimales et sans manipuler d’exposants,
ce qui améliore la lisibilité des calculs.
Théorème
de Bayes pour des densités de probabilité [modifier]
Il existe aussi une version du théorème pour les distributions
continues, qui se déduit simplement de la densité jointe des observations et
des paramètres, produit de la vraisemblance par la densité a priori sur les paramètres, par application de
la définition des lois et des densités conditionnelles.
La forme continue du théorème de Bayes peut aussi s'interpréter
comme indiquant que la distribution a
posteriori s’obtient en
multipliant la distribution a
priori, par la vraisemblance, et en effectuant une normalisation (du fait
qu'il s'agit d'une densité de probabilité). En calcul bayésien, on prend donc
l'habitude de travailler avec des signes de proportionnalité plutôt que des
égalités pour diminuer la complexité des expressions puisque les constantes
manquantes se retrouvent par intégration (en principe). Les techniques de
simulation de type Monte Carlo et MCMC n'utilisent d'ailleurs pas ces
constantes de normalisation.
Exemple 1 :
L’exemple le plus connu est le suivant : si l’on observe K
numéros de séries d’appareils, que le plus grand est S, et qu’on les suppose
numérotés à partir de 1, quelle est la meilleure estimation du nombre N
d’appareils existants ? On démontre[réf. nécessaire] que le meilleur estimateur simple est ![]() , et surtout que la précision de
cette estimation croît très vite, même avec de petites valeurs de K.
, et surtout que la précision de
cette estimation croît très vite, même avec de petites valeurs de K.
Exemple 2 :
Autre exemple possible : supposons qu’une proportion p inconnue d’électeurs vote
« oui » avec p ∈ [0,1]. On tire de la population un échantillon de n électeurs parmi lesquels un nombre x a voté « oui ». La fonction
de vraisemblance vaut donc :
![]()
En multipliant cela par la fonction de densité de probabilité a priori de p et en normalisant, on calcule la
distribution de probabilité a
posteriori de p, ce qui injecte l'information
des nouvelles données du sondage. Ainsi, si la probabilité a priori de p est uniforme sur l'intervalle [0,1],
alors la probabilité a posteriori aura la forme d'une fonction bêta.
![]()
la constante étant différente de celle de la fonction de
vraisemblance.
La fonction bêta se retrouve avec une grande régularité
dans ces questions d’estimation. Le calcul de la variation d’entropie entre l’ancienne et la nouvelle
distribution permet de quantifier exactement, en bits, l’information obtenue.
Voir aussi l'article Plan d'expérience et le problème dit du bandit manchot.
Histoire [modifier]

![]()

![]()
À sa mort en avril 1761, Thomas Bayes laisse à Richard Price ses articles non terminés. C'est ce
dernier qui prend l'initiative de publier l'article « An Essay towards
solving a Problem in the Doctrine of Chance » et de l'envoyer à la Royal Society deux ans plus tard2.
D'après Martyn Hooper, il est probable que Richard Price ait lui
même contribué de manière significative à la rédaction de l'article final et
qu'il soit ainsi avec Thomas Bayes l'auteur du théorme connu sous le nom
de théorème de Bayes. Cette erreur d'attribution serait une application de la loi d'éponymie
de Stigler selon
laquelle les découvertes scientifiques sont rarement attribuées à leur premier
auteur2,3.
Inférence
bayésienne [modifier]
Article détaillé : Inférence bayésienne.
Les règles de la théorie mathématique des probabilités s’appliquent à des probabilités en
tant que telles, pas uniquement à leurapplication en tant que fréquences relatives d’évènements aléatoires. On
peut décider de les appliquer à des degrés
de croyanceen certaines propositions. Ces degrés de croyance s’affinent au
regard d’expériences en appliquant le théorème de Bayes.
Le Théorème de Cox-Jaynes justifie aujourd’hui très bien cette
approche, qui n’eut longtemps que des fondements intuitifs et empiriques.
À titre d’exemple, imaginons deux urnes remplies de boules. La
première contient dix (10) boules noires et trente (30) blanches ; la
seconde en a vingt (20) de chaque. On tire sans préférence particulière une des
urnes au hasard et dans cette urne, on tire une boule au hasard. La boule est
blanche. Quelle est la probabilité qu'on ait tiré cette boule dans la première
urne sachant qu'elle est blanche ?
Intuitivement, on comprend bien qu'il est plus probable que cette
boule provienne de la première urne, que de la seconde. Donc, cette probabilité
devrait être supérieure à 50 %. La réponse exacte (le nombre de boules
blanches de la première urne divisé par le nombre de boules blanches total,
soit 30/50=60 %) peut se calculer à partir du théorème de Bayes.
Soit H1 l’hypothèse « On tire dans la
première urne. » et H2 l’hypothèse « On tire dans la
seconde urne. ». Comme on tire sans préférence particulière, P(H1) = P(H2) ;
de plus, comme on a certainement tiré dans une des deux urnes, la somme des
deux probabilités vaut 1 : chacune vaut 50 %.
Notons D l’information donnée « On tire
une boule blanche. » Comme on tire une boule au hasard dans une des urnes,
la probabilité de D sachant l'hypothèse H1 réalisée vaut :
![]()
De même la probabilité de D sachant l'hypothèse H2 réalisée vaut :
![]()
La formule de Bayes dans le cas discret nous donne donc.
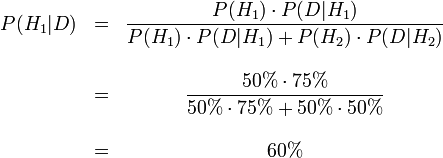
Avant que l’on regarde la couleur de la boule, la probabilité
d’avoir choisi la première urne est une probabilité a-priori, P(H1) soit
50 %. Après avoir regardé la boule, on révise notre jugement et on
considère P(H1|D),
soit 60 %, ce qui confirme notre intuition première.
Pronostics contradictoires [modifier]
· Une station
météo A prévoit du beau temps pour demain.
· Une autre,
B, prévoit au contraire de la pluie.
· On sait que
dans le passé A s’est trompée 25 % du temps dans ses prévisions, et B
30 % du temps.
· On sait
aussi qu’en moyenne 40 % des jours sont de beau temps et 60 % de
pluie.
Qui croire, et avec quelle probabilité ?
Cette approche bayésienne est utilisée par les centres anti-poison pour détecter le plus vite possible et
avec le maximum de précision le type d’empoisonnement dont souffre probablement
un patient.
Aspects sociaux,
juridiques et politiques [modifier]
Un problème régulièrement soulevé par l’approche bayésienne est le
suivant : si une probabilité de comportement (délinquance, par exemple)
est fortement dépendante de certains facteurs sociaux, culturels ou héréditaires,
alors :
· d’un côté,
on peut se demander si cela ne suppose pas une partielle réduction de responsabilité,
morale à défaut de juridique des délinquants. Ou, ce qui revient au même, à une
augmentation de responsabilité de la société, qui n’a pas su ou pas pu
neutraliser ces facteurs.
· d’un autre
côté, on peut souhaiter utiliser cette information pour orienter au mieux une
politique de prévention,
et il faut voir si l’intérêt public ou la morale s’accommoderont de cette
discrimination de facto des citoyens (fût-elle positive).
« Faux
positifs » médicaux [modifier]
Article détaillé : Faux positif.
Les faux positifs sont une difficulté inhérente à tous
les tests : aucun test n’est parfait. Parfois, le résultat sera positif à
tort, ce que l’on nomme parfois risque
du premier ordre ou risque alpha.
Par exemple, quand on teste une personne pour savoir si elle est
infectée par une maladie, il y a un risque généralement infime que le résultat
soit positif alors que le patient n’a pas contracté la maladie. Le problème
alors n’est pas de mesurer ce risque dans l’absolu (avant de procéder au test),
il faut encore déterminer la probabilité qu’un test positif le soit à tort.
Nous allons montrer comment, dans le cas d’une maladie très rare, le même test
par ailleurs très fiable peut aboutir à une nette majorité de positifs
illégitimes.
Imaginons un test extrêmement fiable :
· si un
patient a contracté la maladie, le test le fait remarquer, c’est-à-dire est positif, presque
systématiquement, 99 % des fois, soit avec une probabilité 0,99 ;
· si un
patient est sain, le test est correct, c’est-à-dire négatif dans 95 % des cas, soit avec une
probabilité 0,95 ;
Imaginons que la maladie ne touche qu’une personne sur mille, soit
avec une probabilité 0,001. Cela peut paraître peu mais dans le cas d’une
maladie mortelle, c’est considérable. Nous avons toutes les informations
nécessaires pour déterminer la probabilité qu’un test soit positif à tort, ce
qui peut causer un surdiagnostic.
Désignons par A l’évènement « Le patient a
contracté la maladie » et par B l’évènement « Le test est positif ».
La seconde forme du théorème de Bayes dans le cas discret donne alors :
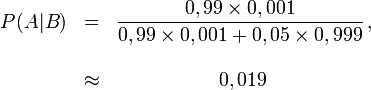
Sachant que le test est positif, la probabilité que le patient soit
sain vaut donc environ : (1 − 0,019) = 0,981. Du fait du très petit
nombre de malades,
·
pratiquement tous les malades présentent un test
positif, mais
·
pratiquement aussi, tous les tests positifs
désignent des porteurs sains.
Si le traitement est très lourd, coûteux ou dangereux pour un
patient sain, il peut être alors opportun de faire subir à tous les patients
positifs un test complémentaire (qui sera sans doute plus précis et plus
coûteux, le premier test n’ayant servi qu’à écarter les cas les plus évidents).
On a tout de même réussi avec le premier test à isoler une
population vingt fois moindre qui contient pratiquement tous les
malades. En procédant à d’autres tests, on peut espérer améliorer la fiabilité
du test. Le théorème de Bayes nous montre que dans le cas d’une probabilité
faible de la maladie recherchée, le risque d’être déclaré positif à tort a un
impact très fort sur la fiabilité. Le dépistage d'une maladie rare telle que le
cancer peut causer le surdiagnostic.
Cette erreur intuitive commune d'estimation est un biais cognitif
appelé "oubli de la fréquence de base".
Bibliographie [modifier]
·
(en) T. Bayes (1763), « An Essay towards solving a Problem in the
Doctrine of Chances », Philosophical
Transactions of the Royal Society of London, 53:370-418.
·
(en) T. Bayes (1763/1958) « Studies in the History of Probability and
Statistics: IX. Thomas Bayes’s Essay Towards Solving a Problem in the Doctrine
of Chances »,Biometrika 45:296-315 (Bayes’s essay in modernized
notation)
·
(en) T. Bayes « An essay towards solving a Problem in the
Doctrine of Chances » (Bayes's essay in the
original notation)
·
(en) Richard Price, « A demonstration of the second rule in the essay towards the
solution of a problem in the doctrines of chances », Philosophical Transactions,vol. 54,
1964, p. 296-325
·
(fr) P.S. Laplace (1774) « Mémoire sur la Probabilité des Causes
par les Événements, » Savants
Étranges 6:621-656, ou bien Œuvres complètes 8:27-65.
·
(en) G.A. Barnard. (1958) « Studies in the History of Probability and
Statistics: IX. Thomas Bayes's Essay Towards Solving a Problem in the Doctrine
of Chances »,Biometrika 45:293-295 (biographical remarks)
·
(en) S.M. Stigler (1982) « Thomas Bayes' Bayesian Inference, » Journal of the Royal Statistical
Society, Series A, 145:250-258 (Stigler
argues for a revised interpretation of the essay -- recommended)
·
(en) A. Papoulis (1984), Probability,
Random Variables, and Stochastic Processes, second edition. New York: McGraw-Hill.
·
(en) S.M. Stigler (1986), « Laplace's 1774 memoir on inverse
probability, » Statistical
Science, 1(3):359--378.
·
(en) S.E. Fienberg (2005) When did Bayesian Inference become
"Bayesian"? Bayesian Analysis, pp. 1-40
· (en) Sharon Bertsch McGrayne, The Theory That Would Not Die : How Bayes' Rule Cracked the Enigma Code, Hunted Down Russian Submarines, and Emerged Triumphant from Two Centuries of Controversy, Yale University Press, 2011
·
(en) Jeff Miller Earliest Known Uses of Some of the Words of Mathematics
(B) (very informative -- recommended)
·
(en) D. Covarrubias « An Essay Towards Solving
a Problem in the Doctrine of Chances » (an outline and exposition of Bayes's essay)
Émission de radio [modifier]
·
Une formule mathématique universelle existe-t-elle ?, France Culture,
Science publique, 9 novembre 2012