| tout |
Y-DNA I SŁOWO, MTDNA I
BRZMIENIE – NIE TYLKO LESZCZYŃSKI |
Y-ADN
ET MOT, MTDNA ET SON - PAS SEULEMENT LESZCZYŃSKI |
Y-DNA
AND WORD, MTDNA AND SOUND - NOT ONLY LESZCZYŃSKI |
Y-DNA
E PALAVRA, MTDNA E SOM - NÃO APENAS LESZCZYŃSKI |
|
| polonais |
PAŹDZIERNIK 3,
2018RUDAWEB 52 KOMENTARZE |
|
|
|
|
| francais |
|
|
|
|
|
| anglais |
W genetycznych
rodach indoeuropejskich słownictwo jest sprawą
ojców. Nauki wymawiania głosek udzielają
matki. Współcześni potomkowie Słowian i Ariów są
sobie bliscy genetycznie, natomiast ich towarzyszki
życia dzieli wyraźny dystans. Najbliższe
słowiańskiemu słownictwu jest litewskie i… irlandzkie.
Artykułowanie głosek najbliższe Polkom i Ukrainkom mają…
Kurdyjki. Najbliżsi źródłom Słowiańszczyzny
wydają się Słoweńcy. |
Dans la lignée
génétique indo-européenne, le vocabulaire est l'affaire des pères. La mère
apprend à prononcer les sons. Les descendants modernes des Slaves et des
Aryens sont génétiquement proches les uns des autres, tandis que leurs
compagnons de vie sont séparés par une nette distance. Les plus proches du
vocabulaire slave sont le lituanien et… l'irlandais. Articuler les sons les
plus proches des femmes polonaises et ukrainiennes… des femmes kurdes. Les
Slovènes semblent être les plus proches des sources de la région slave. |
In the
Indo-European genetic lineage, the vocabulary is a matter for the fathers.
The mother teaches how to pronounce the sounds. The modern descendants of the
Slavs and Aryans are genetically close to each other, while their life
companions are separated by a clear distance. The closest to the Slavic
vocabulary is Lithuanian and… Irish. Articulating sounds closest to Polish
and Ukrainian women… Kurdish women. The Slovenes seem to be closest to the
sources of the Slavic region. |
Na linhagem
genética indo-européia, o vocabulário é assunto dos pais. A mãe ensina a
pronunciar os sons. Os descendentes modernos dos eslavos e arianos são
geneticamente próximos uns dos outros, enquanto seus companheiros de vida são
separados por uma distância clara. O mais próximo do vocabulário eslavo é o
lituano e... o irlandês. Articulando sons mais próximos das mulheres
polonesas e ucranianas... mulheres curdas. Os eslovenos parecem estar mais
próximos das fontes da região eslava. |
In der
indogermanischen Erblinie ist das Vokabular Sache der Väter. Die Mutter
lehrt, wie man die Laute ausspricht. Die modernen Nachkommen der Slawen und
Arier stehen sich genetisch nahe, während ihre Lebensgefährten durch eine
deutliche Distanz getrennt sind. Dem slawischen Wortschatz am nächsten kommen
Litauisch und … Irisch. Laute zu artikulieren, die polnischen und
ukrainischen Frauen am nächsten kommen… kurdischen Frauen. Die Slowenen
scheinen den Quellen der slawischen Region am nächsten zu sein. |
| portuguais |
To niektóre wnioski z tegorocznej pracy zespołu badaczy
z uniwersytetu szanghajskiego – Menghan Zhang, Hong-Xiang Zheng, Shi Yan i Li
Jin – pod tytułem „Reconcilling the father tongue and mather tongue
hypothesis in Indo-European populations”. Są to studia
genetyczno-językowe nad 34. współczesnymi populacjami
indoeuropejskimi w celu sprawdzenia prawdziwości teorii o języku
ojca i języku matki. Pierwsza z nich twierdzi, że język
dziedziczy się po przodkach męskich, zaś druga, że po
żeńskich. Autorzy stwierdzili, że genetyczne i lingwistyczne
dystanse znacznie korelują ze sobą, a nie tylko z
odległościami geograficznymi pomiędzy populacjami.
Jednakże, kiedy śledzimy poszczególne kierunki geograficzne, to
potwierdza się związek między genami ojcowskimi a
słownictwem oraz między macierzyńskimi a fonemami. Inaczej
formułując, Y-DNA jest odpowiedzialne za przenoszenie leksyki
(słownictwa), a mtDNA – fonemów (podstawowych dźwięków mowy). |
Telles sont
quelques-unes des conclusions des travaux menés cette année par une équipe de
chercheurs de l'Université de Shanghai - Menghan Zhang, Hong-Xiang Zheng, Shi
Yan et Li Jin - sous le titre "Réconcilier l'hypothèse de la langue
maternelle et de la langue maternelle dans les populations
indo-européennes". ". Il s'agit d'études génético-linguistiques de
34 populations indo-européennes contemporaines afin de tester la validité des
théories sur la langue du père et la langue de la mère. Le premier prétend
que la langue est héritée d'ancêtres masculins, tandis que le second que la
langue est héritée d'ancêtres féminins. Les auteurs ont constaté que les
distances génétiques et linguistiques sont significativement corrélées entre
elles, et pas seulement avec les distances géographiques entre les
populations. Cependant, lorsque l'on suit des directions géographiques
particulières, la relation se confirme entre gènes paternels et vocabulaire,
et entre maternel et phonèmes. En d'autres termes, l'ADN-Y est responsable du
transport du lexique (vocabulaire) et de l'ADNmt - des phonèmes (sons de base
de la parole). |
These are some
of the conclusions of this year's work by a team of researchers from Shanghai
University - Menghan Zhang, Hong-Xiang Zheng, Shi Yan and Li Jin - under the
title "Reconcilling the father tongue and mather tongue hypothesis in
Indo-European populations". These are genetic-linguistic studies of 34
contemporary Indo-European populations in order to test the validity of
theories about the father's language and the mother's language. The first one
claims that the language is inherited from male ancestors, while the second
one that the language is inherited from female ancestors. The authors found
that genetic and linguistic distances significantly correlate with each
other, not just with geographic distances between populations. However, when
we follow particular geographic directions, the relationship is confirmed
between paternal genes and vocabulary, and between maternal and phonemes. In
other words, Y-DNA is responsible for carrying lexis (vocabulary), and mtDNA
- for phonemes (basic sounds of speech). |
Estas são
algumas das conclusões do trabalho deste ano de uma equipa de investigadores
da Universidade de Xangai - Menghan Zhang, Hong-Xiang Zheng, Shi Yan e Li Jin
- sob o título "Reconciliando a hipótese da língua materna e da língua
matemática nas populações indo-europeias ". São estudos
genético-linguísticos de 34 populações indo-européias contemporâneas para
testar a validade das teorias sobre a língua do pai e a da mãe. A primeira
afirma que a língua é herdada de ancestrais masculinos, enquanto a segunda
que a linguagem é herdada de ancestrais femininos. Os autores descobriram que
as distâncias genéticas e linguísticas se correlacionam significativamente
umas com as outras, não apenas com as distâncias geográficas entre as
populações. No entanto, quando seguimos direções geográficas particulares,
confirma-se a relação entre genes paternos e vocabulário, e entre maternos e
fonemas. Em outras palavras, Y-DNA é responsável por transportar léxico
(vocabulário), e mtDNA - por fonemas (sons básicos da fala). |
Dies sind
einige der Schlussfolgerungen der diesjährigen Arbeit eines Forscherteams der
Universität Shanghai – Menghan Zhang, Hong-Xiang Zheng, Shi Yan und Li Jin –
unter dem Titel „Reconcilling the Father Language and Mather Tongue
Hypothesis in Indo-European Populations ". Dies sind
genetisch-linguistische Studien von 34 zeitgenössischen indogermanischen
Populationen, um die Gültigkeit von Theorien über die Sprache des Vaters und
die Sprache der Mutter zu testen. Der erste behauptet, dass die Sprache von
männlichen Vorfahren geerbt wird, während der zweite behauptet, dass die
Sprache von weiblichen Vorfahren geerbt wird. Die Autoren fanden heraus, dass
genetische und sprachliche Distanzen signifikant miteinander korrelieren,
nicht nur mit geografischen Distanzen zwischen Populationen. Wenn wir jedoch
bestimmten geografischen Richtungen folgen, wird die Beziehung zwischen
väterlichen Genen und Vokabular und zwischen mütterlichen und Phonemen
bestätigt. Mit anderen Worten, Y-DNA ist für das Tragen von Lexik
(Wortschatz) und mtDNA - für Phoneme (Grundlaute der Sprache) verantwortlich. |
| allemand |
W omawianej pracy zestawiono haplogrupy z
językami. W męskich DNA jedyna mutacja
wydzielona spośród ojcowskich to R1a. Wykazuje
ona, co nie jest żadną niespodzianką, związek z
językami słowiańskimi oraz indoirańskimi. Najwyższym
jej udziałem odznaczają się Polacy, Afgańczycy i Sindhi.
R ogólnie (bez podziałów) najczęściej występuje
wśród Irlandczyków, Anglików, Francuzów, Hiszpanów i Portugalczyków, co
też nie jest niespodzianką. Ciekawiej wygląda związek
haplogrup żeńskich z grupami językowymi. M dominuje w
indyjskich, zaś H w europejskich. W miarę równomierny w obu tych
grupach językowych jest udział U, ale zdecydowanie mniej zaznaczony
od dwóch pierwszych. |
Dans ce
travail, les haplogroupes et les langues ont été comparés. Dans l'ADN
masculin, la seule mutation distinguée parmi les paternelles est R1a. Il
montre, sans surprise, un lien avec les langues slaves et indo-iraniennes.
Les Polonais, les Afghans et les Sindhi ont la part la plus élevée. R
généralement (sans divisions) est le plus courant chez les irlandais, les
anglais, les français, les espagnols et les portugais, ce qui n'est pas non
plus une surprise. La relation entre les haplogroupes féminins et les groupes
linguistiques semble plus intéressante. M est dominant en indien et H
dominant en européen. La part de U est relativement égale dans ces deux
groupes linguistiques, mais nettement moins marquée que dans les deux
premiers. |
In this work,
haplogroups and languages were compared. In the male DNA, the only mutation
identified among the paternal ones is R1a. It shows, not surprisingly, a
connection with the Slavic and Indo-Iranian languages. Poles, Afghans and
Sindhi have the highest share. R generally (without divisions) is most common
among Irish, English, French, Spanish and Portuguese, which is also no
surprise. The relationship between female haplogroups and linguistic groups
looks more interesting. M is dominant in Indian and H dominant in European.
The share of U is relatively even in both of these language groups, but
definitely less marked than the first two. |
Neste
trabalho, haplogrupos e línguas foram comparados. No DNA masculino, a única
mutação distinguida entre as paternas é a R1a. Mostra, não
surpreendentemente, uma conexão com as línguas eslava e indo-iraniana.
Poloneses, afegãos e sindi têm a maior participação. R geralmente (sem
divisões) é mais comum entre irlandeses, ingleses, franceses, espanhóis e
portugueses, o que também não é surpresa. A relação entre haplogrupos
femininos e grupos linguísticos parece mais interessante. M é dominante em
indiano e H dominante em europeu. A proporção de U é relativamente uniforme
em ambos os grupos linguísticos, mas definitivamente menos acentuada do que
nos dois primeiros. |
In dieser
Arbeit wurden Haplogruppen und Sprachen verglichen. In der männlichen DNA ist
die einzige Mutation, die sich von den väterlichen unterscheidet, R1a. Es
zeigt, nicht überraschend, eine Verbindung mit den slawischen und
indo-iranischen Sprachen. Polen, Afghanen und Sindhi haben den höchsten
Anteil. R ist im Allgemeinen (ohne Unterteilungen) am häufigsten in Irisch,
Englisch, Französisch, Spanisch und Portugiesisch, was auch keine
Überraschung ist. Interessanter sieht die Beziehung zwischen weiblichen
Haplogruppen und Sprachgruppen aus. M ist dominant in Indien und H dominant
in Europäisch. Der Anteil von U ist in diesen beiden Sprachgruppen relativ
gleichmäßig, aber deutlich weniger ausgeprägt als in den ersten beiden. |
| |
|
|
|
|
|
| |
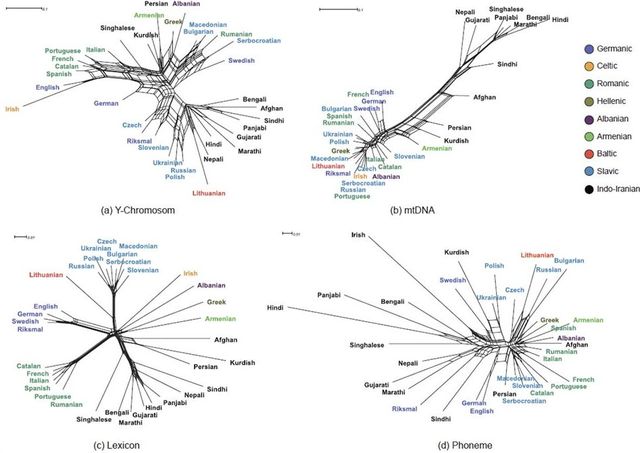
Powyżej inny
wykres z tej pracy (Fig. 2), na którym przedstawiono sieć
sąsiedztwa 34. populacji indoeuropejskich. |
Ci-dessus, un
autre graphique issu de ces travaux (Fig. 2), qui montre le réseau de
voisinage de 34 populations indo-européennes. |
Above is
another graph from this work (Fig. 2), which shows the neighborhood network
of 34 Indo-European populations |
Acima está
outro gráfico deste trabalho (Fig. 2), que mostra a rede de vizinhança de 34
populações indo-europeias. |
Oben ist eine
weitere Grafik aus dieser Arbeit (Abb. 2), die das Nachbarschaftsnetzwerk von
34 indogermanischen Populationen zeigt. . |
| irlandais |
Okazało
się, że genetycznie Czesi są bardziej oddaleni
od Słowian Północnych (w tym Polaków) niż
Norwegowie. Południowi Słowianie są
bliżsi Kurdom, Irańczykom, Ormianom, Grekom i Szwedom. Jednak oprócz Słoweńców, którzy – bardziej
niż wspomniani Czesi –
są bliscy Słowianom Północnym i Norwegom. Pod kątem zbieżności słownictwa
wszystkie współczesne, badane ludy podzielono na ogólnie znane podgrupy
językowe (słowiańskie, romańskie, germańskie itd.).
Ze Słowian najbliżej hipotetycznego centrum indoeuropejskiego
znaleźli się Słoweńcy, a z Indoirańczyków –
Persowie, Pendżabowie, Bengalczycy i użytkownicy hindi, czyli
najpowszechniejszego języka Indii. Pozornie zaskakuje małe
oddalenie Anglików. Jednak przypomnę, że analiza dotyczy
języków w dzisiejszych ich postaciach – w zglobalizowanym świecie
kultury anglosaskiej. Z tego wykresu można wysnuć jeszcze jeden
zaskakujący wniosek – dla słowiańskich najbliższe są
litewski (co nie jest dziwne) i… irlandzki. |
Il
s'est avéré que génétiquement les Tchèques sont plus éloignés des Slaves du
Nord (y compris les Polonais) que des Norvégiens. Les Slaves du Sud sont plus
proches des Kurdes, des Iraniens, des Arméniens, des Grecs et des Suédois.
Cependant, mis à part les Slovènes, qui - plus que les Tchèques ne l'ont
mentionné - sont proches des Slaves du Nord et des Norvégiens. En termes de
convergence de vocabulaire, tous les peuples étudiés contemporains ont été
divisés en sous-groupes linguistiques généralement connus (slave, romain,
germanique, etc.). Parmi les Slaves, les Slovènes étaient les plus proches de
l'hypothétique centre indo-européen, et des Indo-Iraniens - les Perses, le
Pendjab, les Bengalis et les locuteurs de l'hindi, la langue indienne la plus
courante. Apparemment, la petite distance des Anglais est surprenante.
Cependant, permettez-moi de vous rappeler que l'analyse concerne les langues
telles qu'elles sont aujourd'hui - dans le monde globalisé de la culture
anglo-saxonne. Une autre conclusion surprenante peut être tirée de ce tableau
- pour les Slaves, les plus proches sont le Lituanien (ce qui n'est pas
surprenant) et… l'Irlandais. |
It
turned out that the Czechs are genetically more distant from the North Slavs
(including Poles) than the Norwegians. South Slavs are closer to Kurds,
Iranians, Armenians, Greeks and Swedes. However, apart from the Slovenes, who
- more than the Czechs mentioned - are close to the North Slavs and the
Norwegians. In terms of vocabulary convergence, all contemporary studied
peoples were divided into generally known linguistic subgroups (Slavic,
Roman, Germanic, etc.). Of the Slavs, the Slovenes were the closest to the
hypothetical Indo-European center, and of the Indo-Iranians - the Persians,
Punjab, Bengalis and speakers of Hindi, the most common Indian language.
Apparently, the small distance of the English is surprising. However, let me
remind you that the analysis concerns languages as they are
today - in the globalized world of Anglo-Saxon culture. One more surprising
conclusion can be drawn from this chart - for Slavic people the closest are
Lithuanian (which is not surprising) and… Irish. . |
Descobriu-se
que geneticamente tchecos estão mais distantes dos eslavos do norte
(incluindo poloneses) do que os noruegueses. Os eslavos do sul estão mais
próximos de curdos, iranianos, armênios, gregos e suecos. No entanto, além
dos eslovenos, que - mais do que os tchecos mencionaram - estão próximos dos
eslavos do norte e dos noruegueses. Em termos de convergência de vocabulário,
todos os povos contemporâneos estudados foram divididos em subgrupos
linguísticos geralmente conhecidos (eslavos, romanos, germânicos etc.). Dos
eslavos, os eslovenos eram os mais próximos do hipotético centro
indo-europeu, e dos indo-iranianos - os persas, punjab, bengalis e falantes
do hindi, a língua indiana mais comum. Aparentemente, a pequena distância dos
ingleses é surpreendente. No entanto, deixe-me lembrá-lo que a análise diz
respeito às línguas como elas são hoje – no mundo globalizado da cultura
anglo-saxônica. Mais uma conclusão surpreendente pode ser tirada deste
gráfico - para os eslavos, os mais próximos são os lituanos (o que não é
surpreendente) e... os irlandeses. . |
Es
stellte sich heraus, dass Tschechen genetisch weiter von den Nordslawen
(einschließlich Polen) entfernt sind als die Norweger. Südslawen stehen
Kurden, Iranern, Armeniern, Griechen und Schweden näher. Allerdings abgesehen
von den Slowenen, die - mehr als die erwähnten Tschechen - den Nordslawen und
den Norwegern nahestehen. Hinsichtlich der Wortschatzkonvergenz wurden alle
zeitgenössischen untersuchten Völker in allgemein bekannte sprachliche
Untergruppen (Slawisch, Romanisch, Germanisch usw.) eingeteilt. Von den
Slawen waren die Slowenen dem hypothetischen indogermanischen Zentrum am
nächsten, und von den Indo-Iranern - den Persern, Punjab, Bengalen und
Sprechern von Hindi, der am weitesten verbreiteten indischen Sprache.
Offenbar überrascht die geringe Distanz der Engländer. Ich möchte Sie jedoch
daran erinnern, dass die Analyse Sprachen betrifft, wie sie heute sind – in
der globalisierten Welt der angelsächsischen Kultur. Eine weitere
überraschende Schlussfolgerung kann aus dieser Tabelle gezogen werden - für
slawische Menschen sind Litauer (was nicht überraschend ist) und … Iren am
nächsten. . |
| |
Po Y-DNA i leksyce,
czas na mtDNA i fonemy. Pod względem genetycznym rzuca
się w oczy ogromny dystans między Europejkami a Hinduskami, przy dużej zwartości tych pierwszych. Natomiast
Ormianki, Kurdyjki, Iranki i Afganki znalazły się kolejno na
długiej przestrzeni między Europą a Indiami. W fonetyce
zanotowano możliwe do przewidzenia duże oddalenie hindi i
irlandzkiego. Natomiast zaskakująca wydaje się bliskość
polskiego i ukraińskiego z kurdyjskim. |
Après l'ADN-Y
et les lexiques, place à l'ADNmt et aux phonèmes. En termes de génétique, il
y a une énorme distance entre les femmes européennes et indiennes, les
premières étant très compactes. En revanche, les femmes arméniennes, kurdes,
iraniennes et afghanes se sont retrouvées successivement dans le long espace
entre l'Europe et l'Inde. La grande distance prévisible entre l'hindi et
l'irlandais est notée dans la phonétique. En revanche, la proximité du
polonais et de l'ukrainien avec le kurde semble surprenante. |
After Y-DNA
and lexics, it's time for mtDNA and phonemes. In terms of genetics, there is
a huge distance between Europeans and Indian women, with the former being
very compact. On the other hand, Armenians, Kurdish, Iranian and Afghan women
found themselves successively in the long space between Europe and India. The
foreseeable great distance between Hindi and Irish is noted in the phonetics.
On the other hand, the closeness of Polish and Ukrainian with Kurdish seems
surprising. |
Depois de
Y-DNA e léxicos, é hora de mtDNA e fonemas. Em termos de genética, há uma
distância enorme entre as mulheres europeias e indianas, sendo as primeiras
muito compactas. Por outro lado, mulheres armênias, curdas, iranianas e
afegãs se viram sucessivamente no longo espaço entre a Europa e a Índia. A
grande distância previsível entre hindi e irlandês é notada na fonética. Por
outro lado, a proximidade dos poloneses e ucranianos com os curdos parece
surpreendente. |
Nach Y-DNA und
Lexika ist es Zeit für mtDNA und Phoneme. In Bezug auf die Genetik gibt es
eine große Distanz zwischen Europäern und indischen Frauen, wobei erstere
sehr kompakt sind. Auf der anderen Seite fanden sich armenische, kurdische,
iranische und afghanische Frauen nacheinander in dem langen Raum zwischen
Europa und Indien wieder. Die absehbare große Distanz zwischen Hindi und
Irisch macht sich in der Phonetik bemerkbar. Andererseits scheint die Nähe
des Polnischen und Ukrainischen zum Kurdischen überraschend. |
| chinois |
Badanie
chińskiego zespołu rysuje ogólne zależności między
językami a genami ich użytkowników. Zostało wykonane w
oparciu o podstawowe haplogrupy. Bez ich
zróżnicowania na mutacje, co ma znaczenie przy dokładnym
przyporządkowywaniu relacji między DNA a odmianami ludzkiej mowy.
Jednak jest kolejnym, które bezsprzecznie wiąże słownictwo
narodów z ich genotypami, przede wszystkim męskimi. Ponadto, nawet na
takim poziomie ogólności przynosi kilka ciekawych spostrzeżeń,
które mogą być użyteczne w odczytaniu zagadek etnogenezy ludów
indoeuropejskich. |
L'étude de
l'équipe chinoise dessine des relations générales entre les langues et les
gènes de leurs locuteurs. Il a été fait sur la base des haplogroupes de base.
Sans leur différenciation en mutations, ce qui est important pour la
cartographie exacte de la relation entre l'ADN et les variétés de la parole
humaine. Cependant, c'en est une autre qui relie incontestablement le
vocabulaire des nations à leurs génotypes, essentiellement masculins. De
plus, même à un niveau aussi général, il apporte quelques éclairages
intéressants qui peuvent être utiles pour déchiffrer les mystères de
l'ethnogenèse des peuples indo-européens. |
The Chinese
team's study draws general relationships between languages and the genes of
their speakers. It was made on the basis of the basic haplogroups. Without
their differentiation into mutations, which is important for the exact
mapping of the relationship between DNA and varieties of human speech.
However, it is another one that unquestionably links the vocabulary of
nations with their genotypes, primarily male. Moreover, even on such a
general level, it brings some interesting insights that may be useful in
deciphering the mysteries of the ethnogenesis of Indo-European peoples. |
O estudo da
equipe chinesa traça relações gerais entre as línguas e os genes de seus
falantes. Foi feito com base nos haplogrupos básicos. Sem sua diferenciação
em mutações, o que é importante para o mapeamento exato da relação entre o
DNA e as variedades da fala humana. No entanto, é outra que liga
inquestionavelmente o vocabulário das nações com seus genótipos,
principalmente masculinos. Além disso, mesmo em um nível tão geral, traz
alguns insights interessantes que podem ser úteis para decifrar os mistérios
da etnogênese dos povos indo-europeus. |
Die Studie des
chinesischen Teams zeichnet allgemeine Beziehungen zwischen Sprachen und den
Genen ihrer Sprecher. Es wurde auf der Grundlage der grundlegenden
Haplogruppen hergestellt. Ohne ihre Differenzierung in Mutationen, die für
die exakte Kartierung der Beziehung zwischen DNA und Varietäten der
menschlichen Sprache wichtig ist. Es ist jedoch eine andere, die das
Vokabular der Nationen unzweifelhaft mit ihren Genotypen, hauptsächlich
männlichen, verbindet. Darüber hinaus bringt es selbst auf einer so
allgemeinen Ebene einige interessante Einsichten, die bei der Entschlüsselung
der Geheimnisse der Ethnogenese der indogermanischen Völker nützlich sein
können. |
| sanscrit |
Irlandczycy i
Słoweńcy, Polki i Kurdyjki |
Femmes
irlandaises et slovènes, polonaises et kurdes |
Irish and
Slovenian, Polish and Kurdish women |
Mulheres
irlandesas e eslovenas, polonesas e curdas |
Irische und
slowenische, polnische und kurdische Frauen |
| |
Powszechność mtDNA
M w populacjach indyjskich – obecnie
najwyższa koncentracja w Tybecie i Japonii, choć bardzo
rozpowszechniona w całej Azji. Są dwie teorie jej pochodzenia –
afrykańska i azjatycka. W Europie najstarsze dwie próbki znaleziono w
słynnej jaskini Goyet, z ok. 35 tys. lat temu. Wszystko wskazuje na to,
że towarzyszyła Ariom najpóźniej od Azji Środkowej –
już od Pamiru i Hindukuszu, a także podnóży Karakorum oraz
była w Indiach miejscowa, gdy przybyli mężczyźni R1a z
Północy. Na subkontynencie indyjskim zdominowała żeńskie
haplogrupy, spychając na plan dalszy europejskie U, które mogło
przyjść z R1a. Skutkiem jest zróżnicowanie
brzmień języków Indii, które
rozwijały się na bazie słownictwa sanskryckiego.
Oczywiście przy porównywaniu języków współczesnych Indii i
Europy należy zawsze brać poprawkę na ich
kilkutysiącletnie rozdzielenie i dystans geograficzny. |
Prévalence de
l'ADNmt M dans les populations indiennes - actuellement la plus forte
concentration au Tibet et au Japon, bien que très répandue dans toute l'Asie.
Il existe deux théories sur son origine - africaine et asiatique. En Europe,
les deux échantillons les plus anciens ont été trouvés dans la célèbre grotte
de Goyet, avec environ 35 000. il y a des années. Tout indique qu'il
accompagnait au plus tard les Arias d'Asie centrale - du Pamir et de l'Hindu
Kush, ainsi que des contreforts du Karakoram, et qu'il était un habitant de
l'Inde lorsque les hommes R1a du Nord sont arrivés. Dans le sous-continent
indien, il dominait les haplogroupes féminins, repoussant au second plan les
Nous européens qui auraient pu provenir de R1a. En conséquence, les sons des
langues indiennes se sont développés sur la base du vocabulaire sanskrit.
Bien sûr, lorsque l'on compare les langues de l'Inde et de l'Europe
contemporaines, il faut toujours tenir compte de leur séparation de plusieurs
milliers d'années et de leur distance géographique. |
MtDNA M
prevalence in Indian populations - currently the highest concentration in
Tibet and Japan, although very widespread throughout Asia. There are two
theories of its origin - African and Asian. In Europe, the oldest two samples
were found in the famous Goyet cave, with approx. 35 thousand. years ago. All
indications are that it accompanied the Arias from Central Asia at the latest
- from the Pamirs and the Hindu Kush, as well as the foothills of the
Karakoram, and was a local in India when the R1a men from the North arrived.
In the Indian subcontinent, it dominated the female haplogroups, pushing into
the background the European Us that might have come from R1a. As a result,
the sounds of the Indian languages developed on the basis of the Sanskrit
vocabulary. Of course, when comparing the languages of contemporary India and
Europe, one should always take into account their several thousand-year
separation and geographical distance. |
Prevalência de
MtDNA M em populações indianas - atualmente a maior concentração no Tibete e
no Japão, embora muito difundida em toda a Ásia. Existem duas teorias de sua
origem - africana e asiática. Na Europa, as duas amostras mais antigas foram
encontradas na famosa caverna de Goyet, com aproximadamente 35 mil. anos
atrás. Tudo indica que acompanhou as Arias da Ásia Central o mais tardar - do
Pamirs e do Hindu Kush, bem como do sopé do Karakoram, e era um local na
Índia quando os homens R1a do Norte chegaram. No subcontinente indiano,
dominou os haplogrupos femininos, empurrando para segundo plano os eus
europeus que poderiam ter vindo de R1a. Como resultado, os sons das línguas
indianas se desenvolveram com base no vocabulário sânscrito. É claro que, ao
comparar as línguas da Índia e da Europa contemporâneas, deve-se sempre levar
em consideração sua separação de vários milhares de anos e distância
geográfica. |
MtDNA
M-Prävalenz in indischen Populationen – derzeit die höchste Konzentration in
Tibet und Japan, obwohl sie in ganz Asien weit verbreitet ist. Es gibt zwei
Theorien über seinen Ursprung - afrikanisch und asiatisch. In Europa wurden
die beiden ältesten Proben in der berühmten Goyet-Höhle mit ca. 35.000
gefunden. Jahre zuvor. Alle Hinweise deuten darauf hin, dass er die Arias
spätestens aus Zentralasien – vom Pamir und dem Hindukusch sowie den
Ausläufern des Karakorum – begleitete und ein Einheimischer in Indien war,
als die R1a-Männer aus dem Norden eintrafen. Auf dem indischen Subkontinent
dominierte es die weiblichen Haplogruppen und verdrängte die europäischen
USA, die möglicherweise von R1a stammten, in den Hintergrund. Dadurch
entwickelten sich die Laute der indischen Sprachen auf der Grundlage des
Sanskrit-Wortschatzes. Natürlich sollte man beim Vergleich der Sprachen des
zeitgenössischen Indiens und Europas immer ihre mehrere tausendjährige
Trennung und geografische Distanz berücksichtigen. |
| |
Podobieństwo
słownictwa irlandzkiego i słowiańskiego przywodzi na
myśl celtycką legendę o twórcy alfabetu Ogham i
języka gaelickiego – Feniusie Farsaidzie. Miał on dać mieszkańcom Zielonej Wyspy pierwsze
pismo i doskonałą mowę stworzoną wraz z 72. jego
uczniami, a przybył ze Scytii, czyli terenów m.in. dzisiejszej Rosji,
Ukrainy i Polski. Można wiązać to wydarzenie z rozwojem
kultury ceramiki sznurowej, której przedstawiciele dotarli na Wyspy
Brytyjskie w III tys. p.n.e. Nazywający się Skotami, przybyli
najpierw do Irlandii, a następnie do Wielkiej Brytanii. Skoti pochodzi
od tego samego terminu co rosyjskie określenie bydła – skot (to
samo znaczenie w staropolskim). Co tożsame jest ze scytyjskim
Skołoti (jak Scytowie sami siebie nazywali). Termin oznaczał
hodowców bydła, dla których te zwierzęta miały szczególną
wartość. Szkocko-rosyjski duet badaczy – Andrew MacEacharn i Anatol
Klyosov – stwierdził, że przodkiem klanów dzisiejszych szkockich
górali był mężczyzna o haplogrupie R1a1, który żył ok.
5 tys. lat temu na Niżu Rosyjskim. Byłby on także przodkiem
„sznurowców”, Scytów i większości współczesnych Polaków. R1a
przybył do Brytanii i Irlandii w paleolicie, czyli w okresie kiedy nie
było jeszcze rolnictwa na tym terenie, a wiązać go można
z R1a-M458, słowiańską mutacją z kultury ceramiki
sznurowej. Tak więc Słowianie/Scytowie mieliby
przynieść na Wyspy pismo, hodowlę i
umiejętność uprawy
roli. Tegoroczne wnioski chińskich badaczy
dają jeszcze jeden argument na rzecz tej teorii, skoro tysiące lat po tych wydarzeniach stwierdzają
duże podobieństwo leksyki irlandzkiej oraz słowiańskiej.
Dodajmy, że irlandzki był jedynym językiem celtyckim
uwzględnionym w przywoływanej pracy. Tak więc kultura
celtycka, jaka do dziś przetrwała, może mieć wspołne
źródła ze Słowiańszczyzną, a nie we wpływach
afrykańsko-iberyjskich. |
La
similitude du vocabulaire irlandais et slave rappelle la légende celtique sur
le créateur de l'alphabet Ogham et de la langue gaélique - Fenius Farsaid. Il
devait donner aux habitants de l'île verte la première écriture et un
discours parfait, créés avec 72 de ses élèves, et il venait de Scythie,
c'est-à-dire la Russie, l'Ukraine et la Pologne d'aujourd'hui. Cet événement
peut être associé au développement de la culture Corded Ware, dont les
représentants ont atteint les îles britanniques au troisième millénaire.
avant notre ère Appelés Skotami, ils sont d'abord venus en Irlande puis en
Grande-Bretagne. Skoti vient du même terme que le terme russe pour le bétail
- skot (même sens en vieux polonais). Qui est le même que le Scoloti scythe
(comme les Scythes s'appelaient eux-mêmes). Le terme désignait les éleveurs
de bétail pour qui ces animaux avaient une valeur particulière. Le duo de
chercheurs écossais-russe - Andrew MacEacharn et Anatol Klyosov - a déclaré
que l'ancêtre des clans montagnards écossais d'aujourd'hui était un homme
avec l'haplogroupe R1a1, qui vivait environ 5 000 personnes. il y a des
années dans les basses terres russes. Il serait aussi l'ancêtre des "
Cordonniers ", des Scythes et de la plupart des Polonais d'aujourd'hui.
R1a est arrivé en Grande-Bretagne et en Irlande au Paléolithique,
c'est-à-dire à une époque où il n'y avait pas encore d'agriculture dans la
région, et il peut être associé à R1a-M458, une mutation slave de la culture
Corded Ware. Ainsi, les Slaves / Scythes apporteraient aux îles des
compétences en écriture, en élevage et en agriculture. Les conclusions des
chercheurs chinois de cette année fournissent un argument de plus en faveur
de cette théorie, puisque des milliers d'années après ces événements, ils
constatent que les lexiques irlandais et slave sont très similaires. Ajoutons
que l'irlandais était la seule langue celtique incluse dans l'ouvrage cité.
Ainsi, la culture celtique qui a survécu à ce jour peut avoir des sources
communes avec la région slave, et non avec des influences afro-ibériques. |
The
similarity of Irish and Slavic vocabulary brings to mind the Celtic legend
about the creator of the Ogham alphabet and the Gaelic language - Fenius
Farsaid. He was to give the inhabitants of the Green Island the first writing
and a perfect speech, created together with 72 of his students, and he came
from Scythia, i.e. today's Russia, Ukraine and Poland. This event can be
associated with the development of the Corded Ware culture, whose
representatives reached the British Isles in the third thousand years. B.C.E.
Called Skotami, they first came to Ireland and then to Great Britain. Skoti
comes from the same term as the Russian term for cattle - skot (same meaning
in Old Polish). Which is the same as the Scythian Scoloti (as the Scythians
called themselves). The term denoted cattle breeders for whom these animals
were of particular value. The Scottish-Russian research duo - Andrew
MacEacharn and Anatol Klyosov - stated that the ancestor of today's Scottish
highlander clans was a man with the R1a1 haplogroup, who lived about 5,000.
years ago in the Russian Lowlands. He would also be the ancestor of the
"Shoemakers", the Scythians and most of today's Poles. R1a came to
Great Britain and Ireland in the Palaeolithic, i.e. at a time when there was
no agriculture in the area yet, and it can be associated with R1a-M458, a
Slavic mutation from the Corded Ware culture. So the Slavs / Scythians would
bring writing, breeding and farming skills to the Islands. This year's
conclusions of Chinese researchers provide one more argument in favor of this
theory, since thousands of years after these events they find that Irish and
Slavic lexis are very similar. Let us add that Irish was the only Celtic
language included in the work cited. Thus, the Celtic culture that has
survived to this day may have common sources with the Slavic region, and not
with African-Iberian influences. |
A
semelhança do vocabulário irlandês e eslavo traz à mente a lenda celta sobre
o criador do alfabeto Ogham e da língua gaélica - Fenius Farsaid. Ele deveria
dar aos habitantes da Ilha Verde a primeira escrita e um discurso perfeito,
criado em conjunto com 72 de seus alunos, e ele veio da Cítia, ou seja, hoje
Rússia, Ucrânia e Polônia. Este evento pode ser associado ao desenvolvimento
da cultura da Corded Ware, cujos representantes chegaram às Ilhas Britânicas
no terceiro milênio. AEC Chamados de Skotami, eles vieram primeiro para a
Irlanda e depois para a Grã-Bretanha. Skoti vem do mesmo termo que o termo
russo para gado - skot (mesmo significado em polonês antigo). Que é o mesmo
que o Scoloti cita (como os citas se chamavam). O termo denotava criadores de
gado para quem esses animais eram de particular valor. A dupla de pesquisa
escocesa-russa - Andrew MacEacharn e Anatol Klyosov - afirmou que o ancestral
dos clãs escoceses de hoje era um homem com o haplogrupo R1a1, que viveu
cerca de 5.000. anos atrás nas planícies russas. Ele também seria o ancestral
dos "Sapateiros", os citas e a maioria dos poloneses de hoje. O R1a
chegou à Grã-Bretanha e à Irlanda no Paleolítico, ou seja, numa época em que
ainda não havia agricultura na área, e pode ser associado ao R1a-M458, uma
mutação eslava da cultura da Cerâmica Cordada. Assim, os eslavos / citas
trariam habilidades de escrita, criação e agricultura para as ilhas. As
conclusões deste ano dos pesquisadores chineses fornecem mais um argumento a
favor dessa teoria, já que milhares de anos após esses eventos eles descobrem
que os léxicos irlandês e eslavo são muito semelhantes. Acrescentemos que o
irlandês foi a única língua celta incluída na obra citada. Assim, a cultura
celta que sobreviveu até hoje pode ter fontes comuns com a região eslava, e
não com influências afro-ibéricas. |
Die
Ähnlichkeit des irischen und slawischen Vokabulars erinnert an die keltische
Legende über den Schöpfer des Ogham-Alphabets und der gälischen Sprache -
Fenius Farsaid. Er sollte den Bewohnern der Grünen Insel die erste Schrift
und eine perfekte Rede geben, geschaffen zusammen mit 72 seiner Schüler, und
er stammte aus Skythen, d.h. das heutige Russland, die Ukraine und Polen.
Dieses Ereignis kann mit der Entwicklung der Corded Ware-Kultur in Verbindung
gebracht werden, deren Vertreter im dritten Jahrtausend die britischen Inseln
erreichten. v. Chr. Skotami genannt, kamen sie zuerst nach Irland und dann
nach Großbritannien. Skoti kommt vom gleichen Begriff wie der russische
Begriff für Rinder – skot (gleiche Bedeutung im Altpolnischen). Das ist
dasselbe wie die skythischen Scoloti (wie sich die Skythen selbst nannten).
Der Begriff bezeichnete Viehzüchter, für die diese Tiere von besonderem Wert
waren. Das schottisch-russische Forscherduo – Andrew MacEacharn und Anatol
Klyosov – erklärte, dass der Vorfahr der heutigen schottischen
Highlander-Clans ein Mann mit der R1a1-Haplogruppe war, der etwa 5.000 Jahre
alt war. Jahren im russischen Tiefland. Er wäre auch der Vorfahre der
„Schuhmacher“, der Skythen und der meisten heutigen Polen. R1a kam im Paläolithikum,
also zu einer Zeit, als es in der Gegend noch keine Landwirtschaft gab, nach
Großbritannien und Irland und kann mit R1a-M458, einer slawischen Mutation
aus der Corded-Ware-Kultur, in Verbindung gebracht werden. So würden die
Slawen / Skythen Schreib-, Zucht- und Landwirtschaftsfähigkeiten auf die
Inseln bringen. Die diesjährigen Schlussfolgerungen chinesischer Forscher
liefern ein weiteres Argument zugunsten dieser Theorie, da sie Tausende von
Jahren nach diesen Ereignissen feststellen, dass irische und slawische Lexika
sehr ähnlich sind. Lassen Sie uns hinzufügen, dass Irisch die einzige
keltische Sprache war, die in dem zitierten Werk enthalten ist. So hat die
bis heute erhaltene keltische Kultur möglicherweise gemeinsame Quellen mit
dem slawischen Raum und nicht mit afrikanisch-iberischen Einflüssen. |
| |
Bliskość
polskiego i ukraińskiego z kurdyjskim w fonetyce. To zaskakujące ustalenie może mieć
związek z mtDNA Kurdyjek. Ivan Nasidze z zespołem, w pracy „MtDNA
and Y‐chromosome
Variation in Kurdish Groups”, zwrócili uwagę na typową dla Kurdyjek
haplogrupę HV1, która pochodzi z tego rejonu świata i jest bliska H
(45 proc. u współczesnych Polek) oraz V. Stwierdzili, że –
spośród zachodnioazjatyckich – w mtDNA populacje kurdyjskie są
najbardziej podobne do europejskich. Ta szczegółowa praca przedstawia
więc trochę inaczej dystans Kurdyjek od Europejek niż zrobili
to Chińczycy, ale – jak już wspominałem – w zakresie genetyki
ich opracowanie jest bardzo ogólne (poza R1a – bez mutacji, kladów itp.). |
La proximité
du polonais et de l'ukrainien avec le kurde en phonétique. Cette découverte
surprenante peut être liée à l'ADNmt kurde. Ivan Nasidze et son équipe, dans
le travail "MtDNA and Y-chromosome Variation in Kurdish Groups",
ont attiré l'attention sur l'haplogroupe kurde typique HV1, qui vient de
cette région du monde et est proche de H (45% chez les femmes polonaises
contemporaines ) et V. Ils ont déclaré que - parmi les Asiatiques occidentaux
- les populations kurdes dans l'ADNmt sont les plus similaires aux
populations européennes. Ce travail détaillé montre une distance légèrement
différente entre les femmes kurdes et les femmes européennes par rapport aux
femmes chinoises, mais - comme je l'ai déjà mentionné - en termes de génétique,
leur développement est très général (sauf pour R1a - sans mutations, clades,
etc.). |
The closeness
of Polish and Ukrainian with Kurdish in phonetics. This surprising finding
may be related to Kurdish mtDNA. Ivan Nasidze and his team, in the work
"MtDNA and Y-chromosome Variation in Kurdish Groups", drew
attention to the typical Kurdish haplogroup HV1, which comes from this region
of the world and is close to H (45% in contemporary Polish women) and V. They
stated that - among the West Asian - the Kurdish populations in mtDNA are
most similar to the European ones. This detailed work shows a slightly
different distance between Kurdish women and European women than the Chinese
did, but - as I have already mentioned - in terms of genetics their
development is very general (except for R1a - without mutations, clades,
etc.). |
A proximidade
do polonês e ucraniano com o curdo na fonética. Essa descoberta surpreendente
pode estar relacionada ao mtDNA curdo. Ivan Nasidze e sua equipe, no trabalho
"MtDNA and Y-chromosome Variation in Kurdish Groups", chamaram a
atenção para o típico haplogrupo curdo HV1, que vem desta região do mundo e
está próximo de H (45% em mulheres polonesas contemporâneas ) e V. Eles
afirmaram que - entre os da Ásia Ocidental - as populações curdas no mtDNA
são mais semelhantes às europeias. Este trabalho detalhado mostra uma
distância ligeiramente diferente entre as mulheres curdas e as mulheres
europeias do que as chinesas, mas - como já mencionei - em termos de genética
seu desenvolvimento é muito geral (exceto R1a - sem mutações, clados etc.). |
Die
phonetische Nähe des Polnischen und Ukrainischen zum Kurdischen. Dieser
überraschende Befund könnte mit kurdischer mtDNA zusammenhängen. Ivan Nasidze
und sein Team machten in der Arbeit „MtDNA and Y-chromosome Variation in
Kurdish Groups“ auf die typische kurdische Haplogruppe HV1 aufmerksam, die
aus dieser Region der Welt stammt und nahe an H liegt (45 % bei
zeitgenössischen polnischen Frauen ) und V. Sie gaben an, dass – unter den
Westasiaten – die kurdischen Populationen in mtDNA den europäischen am
ähnlichsten sind. Diese detaillierte Arbeit zeigt eine etwas andere Distanz
zwischen kurdischen Frauen und europäischen Frauen als die Chinesen, aber -
wie ich bereits erwähnt habe - ihre Entwicklung ist genetisch sehr allgemein
(außer R1a - ohne Mutationen, Kladen usw.). |
| |
Słoweńcy genetycznie
są bliżsi Słowianom Północnym i
Norwegom niż Czesi. Natomiast
językowo wydają
się najbliżej historycznego rdzenia języków
bałtosłowiańskich wśród dzisiejszych Słowian. |
Les Slovènes
sont génétiquement plus proches des Slaves du Nord et des Norvégiens que des
Tchèques. D'autre part, linguistiquement, ils semblent les plus proches du
noyau historique des langues balto-slaves chez les Slaves d'aujourd'hui. |
The Slovenes
are genetically closer to the North Slavs and Norwegians than the Czechs. On
the other hand, linguistically they seem closest to the historical core of
the Balto-Slavic languages among today's Slavs. |
Os eslovenos
são geneticamente mais próximos dos eslavos e noruegueses do norte do que os
tchecos. Por outro lado, linguisticamente eles parecem mais próximos do
núcleo histórico das línguas balto-eslavas entre os eslavos de hoje. |
Die Slowenen
sind den Nordslawen und Norwegern genetisch näher als die Tschechen.
Andererseits scheinen sie dem historischen Kern der baltoslawischen Sprachen
unter den heutigen Slawen sprachlich am nächsten zu sein. |
| |
Największe
zbieżności między słoweńskim a sanskrytem wedyjskim w pracy „Indo-Aryan and Slavic Affinities”
zauważyli Joseph Skulj i Jagdish C. Sharda. Przedstawili bogaty zbiór
wspólnego słownictwa obu języków. Oto fragment ich ustaleń –
najpierw słowo polskie, następnie sanskryckie, a na końcu
słoweńskie: ożywiać adżidżivat oživeti,
ogień agni ogenj, ognisko agnisztha ognjišče, pławić
apuplavat poplaviti, oskubać askauti oskubiti, odsuwać asuvati
suvati, usta auszta usta, boleć balate boleti, bóg bhaga bog, bogaty
bhagavat bogat, bojaźń bhijas bojazen, błyskać bhlasate
bleščati, brat bhratri brat, brew bhru brow, być bhuta biti,
wzburzać bhurati buriti, biegać bes’ati bežati, prawić braviti
praviti, budzić bodhati buditi – itp., itd. |
Les plus
grandes similitudes entre le slovène et le sanskrit védique dans l'ouvrage
"Affinités indo-aryennes et slaves" ont été notées par Joseph Skulj
et Jagdish C. Sharda. Ils ont présenté une riche collection de vocabulaire
commun aux deux langues. Voici un fragment de leurs découvertes - d'abord le
mot polonais, puis le mot sanskrit, et enfin le mot slovène : revive ajijivat
oživeti, fire agni ogenj, agnisztha ogjišče bonfire, swim apuplavat
poplaviti, pluck askauti oskubiti, move asuvćuszógtavati,
bolećuszógtavati, mouth un bolećógtavati bhaga tourbière, riche
bhagavat riche, peur bhijas bojazen, flash bhlasate bleščati, frère
bhratri gosse, sourcil bhru front, être bhuta biti, ébouriffer bhurati
buriti, courir bes'ati bežati, prêcher braviti praviti, réveiller bodhati
buditi - etc., etc., |
The greatest
similarities between Slovenian and Vedic Sanskrit in the work
"Indo-Aryan and Slavic Affinities" were noted by Joseph Skulj and
Jagdish C. Sharda. They presented a rich collection of common vocabulary of
both languages. Here is a fragment of their findings - first the Polish word,
then the Sanskrit word, and finally the Slovenian word: revive ajijivat
oživeti, fire agni ogenj, agnisztha ogjišče bonfire, swim apuplavat
poplaviti, pluck askauti oskubiti, move asuvćuszógtavati,
bolećuszógtavati, mouth a bolećógtavati bhaga bog, rich bhagavat
rich, fear bhijas bojazen, flash bhlasate bleščati, brother bhratri
brat, eyebrow bhru brow, be bhuta biti, ruffle bhurati buriti, run bes'ati
bežati, preach braviti praviti, awaken bodhati buditi - etc., etc., |
As maiores
semelhanças entre o sânscrito esloveno e védico na obra "Afinidades
indo-arianas e eslavas" foram observadas por Joseph Skulj e Jagdish C.
Sharda. Eles apresentaram uma rica coleção de vocabulário comum de ambas as
línguas. Aqui está um fragmento de suas descobertas - primeiro a palavra
polonesa, depois a palavra sânscrita e, finalmente, a palavra eslovena:
reviver ajijivat oživeti, fogo agni ogenj, agnisztha ogjišče fogueira,
nadar apuplavat poplaviti, arrancar askauti oskubiti, mover
asuvćuszógtavati, bolećuszógtavati, boca um bolećógtavati
bhaga pântano, rico bhagavat rico, medo bhijas bojazen, flash bhlasate
bleščati, irmão bhratri pirralho, sobrancelha bhru testa, seja bhuta
biti, ruffle bhurati buriti, corra bes'ati bežati, pregue braviti praviti,
desperte bodhati buditi - etc., etc., |
Die größten
Ähnlichkeiten zwischen slowenischem und vedischem Sanskrit in der Arbeit
„Indo-Aryan and Slavic Affinities“ wurden von Joseph Skulj und Jagdish C.
Sharda festgestellt. Sie präsentierten eine reiche Sammlung von gemeinsamem
Vokabular beider Sprachen. Hier ist ein Fragment ihrer Ergebnisse – zuerst
das polnische Wort, dann das Sanskrit-Wort und schließlich das slowenische
Wort: beleben ajijivat oživeti, Feuer agni ogenj, agnisztha ogjišče
Lagerfeuer, schwimmen apuplavat poplaviti, zupfen askauti oskubiti, bewegen
asuvćuszógtavati, bolećuszógtavati, Mund a bolećógtavati bhaga
sumpf, reich bhagavat reich, angst bhijas bojazen, flash bhlasate
bleščati, bruder bhratri gör, augenbraue bhru stirn, bhuta biti sein,
bhurati buriti kräuseln, bes'ati bežati laufen, braviti praviti predigen,
bodhati buditi erwachen - usw., etc., |
| |
W sanskrycie
wedyjskim mamy najstarsze zapisane formy języka,
którym posługiwali się wspólni przodkowie dzisiejszych
Słowian i Hindusów. Z Europy Środkowej i/lub
Wschodniej, w III i
II tysiącleciu p.n.e., jego użytkownicy
rozprzestrzenili tę mowę od Irlandii po Indie.
To, że najwierniej zachowała się w językach zachodnich
gałęzi Słowian Północnych (do których
należałoby zaliczyć Słoweńców – wbrew przyjętej
klasyfikacji) wskazuje na najbardziej prawdopodobne czasowo, geograficznie i
lingwistycznie źródło współczesnych języków
indosłowiańskich. |
En sanskrit
védique, nous avons les formes écrites les plus anciennes de la langue
utilisées par les ancêtres communs des Slaves et des Hindous d'aujourd'hui.
Venant d'Europe centrale et/ou orientale, aux 3e et 2e millénaires avant
notre ère, ses locuteurs ont diffusé le discours de l'Irlande jusqu'en Inde.
Le fait qu'il ait été le plus fidèlement conservé dans les langues
occidentales des branches des Slaves du Nord (auxquelles les Slovènes
devraient être inclus - contrairement à la classification acceptée) indique
la source la plus probable des langues indo-slaves contemporaines en termes
de temps, de géographie et de linguistique. |
n Vedic
Sanskrit, we have the oldest written forms of the language used by the common
ancestors of today's Slavs and Hindus. From Central and / or Eastern Europe,
in the 3rd and 2nd millennium BC, its speakers spread the speech from Ireland
to India. The fact that it was most faithfully preserved in the western
languages of the branches of the Northern Slavs (to which the Slovenes should
be included - contrary to the accepted classification) indicates the most
probable source of contemporary Indo-Slavic languages in terms of time,
geography and linguistics. |
Em sânscrito
védico, temos as formas escritas mais antigas da língua usada pelos
ancestrais comuns dos eslavos e hindus de hoje. Da Europa Central e/ou
Oriental, no 3º e 2º milênio aC, seus falantes espalharam o discurso da
Irlanda para a Índia. O fato de ter sido preservado mais fielmente nas
línguas ocidentais dos ramos dos eslavos do norte (aos quais os eslovenos
devem ser incluídos - ao contrário da classificação aceita) indica a fonte
mais provável das línguas indo-eslavas contemporâneas em em termos de tempo,
geografia e linguística. |
Im vedischen
Sanskrit haben wir die ältesten schriftlichen Formen der Sprache, die von den
gemeinsamen Vorfahren der heutigen Slawen und Hindus verwendet wurde. Aus
Mittel- und/oder Osteuropa verbreiteten ihre Sprecher im 3. und 2.
Jahrtausend v. Chr. die Rede von Irland bis nach Indien. Die Tatsache, dass
es in den westlichen Sprachen der Zweige der Nordslawen (zu denen die
Slowenen gehören sollten - entgegen der akzeptierten Klassifizierung) am
genauesten erhalten wurde, weist auf die wahrscheinlichste Quelle
zeitgenössischer indoslawischer Sprachen hin zeitlich, geographisch und
sprachlich. |
| |
Zarzucając
małe uszczegółowienie chińskiej pracy pod względem
zastosowanych genotypów, jest ona jeszcze jednym dowodem, jak we współczesnej nauce na całym świecie
upowszechniła się wiedza o powiązaniu ludzkich
haplogrup z używanymi przez poszczególne populacje językami. Udowadnia, że analizy prowadzone w tym kierunku
potrafią sprawdzać trafność różnych teorii
lingwistów czy historyków. |
En accusant un
petit détail du travail chinois en termes de génotypes utilisés, c'est une
preuve supplémentaire que dans la science moderne, les connaissances sur la
connexion des haplogroupes humains avec les langues utilisées par les
populations individuelles se sont répandues dans le monde entier. Il prouve
que les analyses menées dans ce sens permettent de vérifier l'exactitude des
diverses théories des linguistes et des historiens. |
By accusing a
small detail of Chinese work in terms of the genotypes used, it is yet
another proof that in modern science the knowledge about the connection of
human haplogroups with languages used by individual populations has spread
all over the world. He proves that analyzes conducted in this direction can
check the accuracy of various theories of linguists and historians. |
Ao acusar um
pequeno detalhe do trabalho chinês quanto aos genótipos utilizados, é mais
uma prova de que na ciência moderna o conhecimento sobre a ligação dos
haplogrupos humanos com as línguas utilizadas por populações individuais se
espalhou pelo mundo. Ele comprova que análises conduzidas nesse sentido podem
verificar a veracidade de diversas teorias de linguistas e
historiadores. |
Indem ein
kleines Detail der chinesischen Arbeit in Bezug auf die verwendeten Genotypen
beschuldigt wird, ist dies ein weiterer Beweis dafür, dass sich in der
modernen Wissenschaft das Wissen um die Verbindung menschlicher Haplogruppen
mit Sprachen, die von einzelnen Bevölkerungsgruppen verwendet werden, auf der
ganzen Welt verbreitet hat. Er beweist, dass in dieser Richtung durchgeführte
Analysen die Richtigkeit verschiedener Theorien von Linguisten und
Historikern überprüfen können. |
| |
Leszczyński
mówi |
Leszczyński
dit |
Leszczyński
says |
Leszczyński
diz |
sagt
Leszczyński |
| |
Osobom, które
lubią przekaz w formie mówionej polecam, porządkujący stan
wiedzy o korelacji genów z językami, wykład Adriana
Leszczyńskiego. Przedstawił go na III Festiwalu Historycznym, który
odbył się w tym roku w Muchowie. Leszczyński omówił, pod
tytułem „Pochodzenie Słowian według badań genetycznych”,
dotychczasowe wnioski wypływające z ustaleń genetyki w
odniesieniu do Słowian. Zaznaczę tylko, że nie zgadzam
się z wnioskowaniem wyłącznie na podstawie próbek kopalnych,
bo dla Słowiańszczyzny dają niepełny obraz z powodu
obrzędu ciałopalenia. |
Je recommande
une conférence d'Adrian Leszczyński, qui organise l'état des
connaissances sur la corrélation des gènes avec les langues, aux personnes
qui aiment le message sous forme orale. Il l'a présenté au 3e Festival
historique, qui a eu lieu cette année à Muchów. Leszczyński a discuté,
sous le titre "L'origine des Slaves selon la recherche génétique",
les conclusions actuelles résultant des découvertes de la génétique en
relation avec les Slaves. Je soulignerai seulement que je ne suis pas
d'accord avec l'inférence uniquement sur la base d'échantillons fossiles, car
pour les peuples slaves, ils donnent une image incomplète en raison du rite
de la combustion. |
I recommend a
lecture by Adrian Leszczyński, which organizes the state of knowledge
about the correlation of genes with languages, to people who like the message
in spoken form. He presented it at the 3rd Historical Festival, which took
place this year in Muchów. Leszczyński discussed, under the title
"The Origin of the Slavs According to Genetic Research", the
current conclusions resulting from the findings of genetics in relation to
the Slavs. I will only point out that I do not agree with inferring solely on
the basis of fossil samples, because for the Slavic people they give an
incomplete picture due to the rite of burning. |
Recomendo uma
palestra de Adrian Leszczyński, que organiza o estado de conhecimento
sobre a correlação dos genes com as línguas, para as pessoas que gostam da
mensagem na forma falada. Ele o apresentou no 3º Festival Histórico, que
aconteceu este ano em Muchów. Leszczyński discutiu, sob o título "A
Origem dos Eslavos Segundo a Pesquisa Genética", as atuais conclusões
resultantes das descobertas da genética em relação aos eslavos. Ressaltarei
apenas que não concordo em inferir apenas com base em amostras fósseis,
porque para os eslavos eles dão uma imagem incompleta devido ao rito da
queima. |
Wem die
Botschaft in gesprochener Form gefällt, dem empfehle ich einen Vortrag von
Adrian Leszczyński, der den Wissensstand über den Zusammenhang von Genen
mit Sprachen organisiert. Er präsentierte es auf dem 3. Historischen
Festival, das dieses Jahr in Muchów stattfand. Leszczyński erörterte
unter dem Titel "Die Herkunft der Slawen nach genetischer
Forschung" die aktuellen Schlussfolgerungen, die sich aus den
Erkenntnissen der Genetik in Bezug auf die Slawen ergeben. Ich möchte nur darauf
hinweisen, dass ich nicht damit einverstanden bin, nur auf der Grundlage
fossiler Proben zu schließen, weil sie für die Slawen aufgrund des
Verbrennungsritus ein unvollständiges Bild geben. |
| |
Na zdjęciu
głównym fotografia z relacji Adriana Leszczyńskiego ze
Słowenii – cały fotoreportaż na stronie Czesława Białczyńskiego. Proponujemy też wrażenia Polaka z obcowania z
językiem słoweńskim na słowianieukrytahistoriapolski.pl. |
Sur la photo
principale, une photo du compte d'Adrian Leszczyński de Slovénie -
l'intégralité du reportage photo sur le site Web de Czesław
Białczyński. Nous proposons également les impressions d'un Polonais
de communier avec la langue slovène sur le
Slovanieukrytahistoriapolski.pl. |
In the main
photo, a photo from Adrian Leszczyński's account from Slovenia - the
entire photo report on Czesław Białczyński's website. We also
propose the impressions of a Pole from communing with the Slovenian language
on the Slovanieukrytahistoriapolski.pl. |
Na foto
principal, uma foto da conta de Adrian Leszczyński da Eslovênia - toda a
reportagem fotográfica no site de Czesław Białczyński. Também
propomos as impressões de um polonês da comunhão com a língua eslovena no
Slovanieukrytahistoriapolski.pl. |
Auf dem
Hauptfoto ein Foto aus dem Konto von Adrian Leszczyński aus Slowenien -
der gesamte Fotobericht auf der Website von Czesław
Białczyński. Auf Slovanieukrytahistoriapolski.pl schlagen wir auch
die Eindrücke eines Polen aus der Kommunikation mit der slowenischen Sprache
vor. |
| |
Jeśli masz ochotę –
zapisz się na nasz newsletter informujący o nowych wpisach na
naszym blogu. Wystarczy przysłać e-mail z hasłem NEWSLETTER w tytu |
Si vous le
souhaitez, abonnez-vous à notre newsletter pour vous informer des nouvelles
entrées sur notre blog. Il suffit d'envoyer un e-mail avec le mot de passe
NEWSLETTER dans le titre |
If you want -
subscribe to our newsletter informing about new entries on our blog. It is
enough to send an e-mail with the password NEWSLETTER in the title |
Se você quiser
- assine nossa newsletter informando sobre novas entradas em nosso blog.
Basta enviar um e-mail com a senha NEWSLETTER no título |
Wenn Sie
möchten - abonnieren Sie unseren Newsletter, der Sie über neue Einträge in
unserem Blog informiert. Es genügt, eine E-Mail mit dem Passwort NEWSLETTER
im Titel zu senden |
| |
|
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|