| tout |
|
| polonais |
|
| francais |
|
| anglais |
In
der indogermanischen Erblinie ist das Vokabular Sache der Väter. Die Mutter
lehrt, wie man die Laute ausspricht. Die modernen Nachkommen der Slawen und
Arier stehen sich genetisch nahe, während ihre Lebensgefährten durch eine
deutliche Distanz getrennt sind. Dem slawischen Wortschatz am nächsten kommen
Litauisch und … Irisch. Laute zu artikulieren, die polnischen und
ukrainischen Frauen am nächsten kommen… kurdischen Frauen. Die Slowenen
scheinen den Quellen der slawischen Region am nächsten zu sein. |
| portuguais |
Dies
sind einige der Schlussfolgerungen der diesjährigen Arbeit eines
Forscherteams der Universität Shanghai – Menghan Zhang, Hong-Xiang Zheng, Shi
Yan und Li Jin – unter dem Titel „Reconcilling the Father Language and Mather
Tongue Hypothesis in Indo-European Populations ". Dies sind
genetisch-linguistische Studien von 34 zeitgenössischen indogermanischen
Populationen, um die Gültigkeit von Theorien über die Sprache des Vaters und
die Sprache der Mutter zu testen. Der erste behauptet, dass die Sprache von
männlichen Vorfahren geerbt wird, während der zweite behauptet, dass die
Sprache von weiblichen Vorfahren geerbt wird. Die Autoren fanden heraus, dass
genetische und sprachliche Distanzen signifikant miteinander korrelieren,
nicht nur mit geografischen Distanzen zwischen Populationen. Wenn wir jedoch
bestimmten geografischen Richtungen folgen, wird die Beziehung zwischen
väterlichen Genen und Vokabular und zwischen mütterlichen und Phonemen
bestätigt. Mit anderen Worten, Y-DNA ist für das Tragen von Lexik
(Wortschatz) und mtDNA - für Phoneme (Grundlaute der Sprache) verantwortlich. |
| allemand |
In
dieser Arbeit wurden Haplogruppen und Sprachen verglichen. In der männlichen
DNA ist die einzige Mutation, die sich von den väterlichen unterscheidet,
R1a. Es zeigt, nicht überraschend, eine Verbindung mit den slawischen und
indo-iranischen Sprachen. Polen, Afghanen und Sindhi haben den höchsten
Anteil. R ist im Allgemeinen (ohne Unterteilungen) am häufigsten in Irisch,
Englisch, Französisch, Spanisch und Portugiesisch, was auch keine
Überraschung ist. Interessanter sieht die Beziehung zwischen weiblichen
Haplogruppen und Sprachgruppen aus. M ist dominant in Indien und H dominant
in Europäisch. Der Anteil von U ist in diesen beiden Sprachgruppen relativ
gleichmäßig, aber deutlich weniger ausgeprägt als in den ersten beiden. |
| |
|
| |
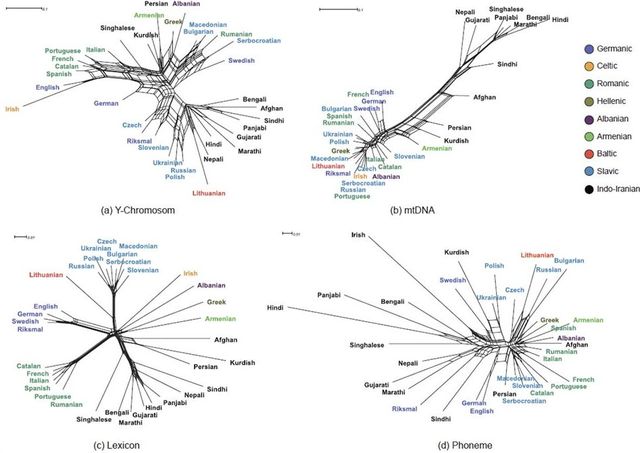
Oben
ist eine weitere Grafik aus dieser Arbeit (Abb. 2), die das
Nachbarschaftsnetzwerk von 34 indogermanischen Populationen zeigt. . |
| irlandais |
Es stellte
sich heraus, dass Tschechen genetisch weiter von den Nordslawen
(einschließlich Polen) entfernt sind als die Norweger. Südslawen stehen
Kurden, Iranern, Armeniern, Griechen und Schweden näher. Allerdings abgesehen
von den Slowenen, die - mehr als die erwähnten Tschechen - den Nordslawen und
den Norwegern nahestehen. Hinsichtlich der Wortschatzkonvergenz wurden alle
zeitgenössischen untersuchten Völker in allgemein bekannte sprachliche
Untergruppen (Slawisch, Romanisch, Germanisch usw.) eingeteilt. Von den
Slawen waren die Slowenen dem hypothetischen indogermanischen Zentrum am
nächsten, und von den Indo-Iranern - den Persern, Punjab, Bengalen und
Sprechern von Hindi, der am weitesten verbreiteten indischen Sprache.
Offenbar überrascht die geringe Distanz der Engländer. Ich möchte Sie jedoch
daran erinnern, dass die Analyse Sprachen betrifft, wie sie heute sind – in
der globalisierten Welt der angelsächsischen Kultur. Eine weitere
überraschende Schlussfolgerung kann aus dieser Tabelle gezogen werden - für
slawische Menschen sind Litauer (was nicht überraschend ist) und … Iren am
nächsten. . |
| |
Nach
Y-DNA und Lexika ist es Zeit für mtDNA und Phoneme. In Bezug auf die Genetik
gibt es eine große Distanz zwischen Europäern und indischen Frauen, wobei
erstere sehr kompakt sind. Auf der anderen Seite fanden sich armenische,
kurdische, iranische und afghanische Frauen nacheinander in dem langen Raum
zwischen Europa und Indien wieder. Die absehbare große Distanz zwischen Hindi
und Irisch macht sich in der Phonetik bemerkbar. Andererseits scheint die
Nähe des Polnischen und Ukrainischen zum Kurdischen überraschend. |
| chinois |
Die
Studie des chinesischen Teams zeichnet allgemeine Beziehungen zwischen
Sprachen und den Genen ihrer Sprecher. Es wurde auf der Grundlage der
grundlegenden Haplogruppen hergestellt. Ohne ihre Differenzierung in
Mutationen, die für die exakte Kartierung der Beziehung zwischen DNA und
Varietäten der menschlichen Sprache wichtig ist. Es ist jedoch eine andere,
die das Vokabular der Nationen unzweifelhaft mit ihren Genotypen,
hauptsächlich männlichen, verbindet. Darüber hinaus bringt es selbst auf
einer so allgemeinen Ebene einige interessante Einsichten, die bei der
Entschlüsselung der Geheimnisse der Ethnogenese der indogermanischen Völker
nützlich sein können. |
| |
Irische
und slowenische, polnische und kurdische Frauen |
| |
MtDNA
M-Prävalenz in indischen Populationen – derzeit die höchste Konzentration in
Tibet und Japan, obwohl sie in ganz Asien weit verbreitet ist. Es gibt zwei
Theorien über seinen Ursprung - afrikanisch und asiatisch. In Europa wurden
die beiden ältesten Proben in der berühmten Goyet-Höhle mit ca. 35.000
gefunden. Jahre zuvor. Alle Hinweise deuten darauf hin, dass er die Arias
spätestens aus Zentralasien – vom Pamir und dem Hindukusch sowie den
Ausläufern des Karakorum – begleitete und ein Einheimischer in Indien war,
als die R1a-Männer aus dem Norden eintrafen. Auf dem indischen Subkontinent
dominierte es die weiblichen Haplogruppen und verdrängte die europäischen
USA, die möglicherweise von R1a stammten, in den Hintergrund. Dadurch
entwickelten sich die Laute der indischen Sprachen auf der Grundlage des
Sanskrit-Wortschatzes. Natürlich sollte man beim Vergleich der Sprachen des
zeitgenössischen Indiens und Europas immer ihre mehrere tausendjährige
Trennung und geografische Distanz berücksichtigen. |
| |
Die
Ähnlichkeit des irischen und slawischen Vokabulars erinnert an die keltische
Legende über den Schöpfer des Ogham-Alphabets und der gälischen Sprache -
Fenius Farsaid. Er sollte den Bewohnern der Grünen Insel die erste Schrift
und eine perfekte Rede geben, geschaffen zusammen mit 72 seiner Schüler, und
er stammte aus Skythen, d.h. das heutige Russland, die Ukraine und Polen.
Dieses Ereignis kann mit der Entwicklung der Corded Ware-Kultur in Verbindung
gebracht werden, deren Vertreter im dritten Jahrtausend die britischen Inseln
erreichten. v. Chr. Skotami genannt, kamen sie zuerst nach Irland und dann
nach Großbritannien. Skoti kommt vom gleichen Begriff wie der russische
Begriff für Rinder – skot (gleiche Bedeutung im Altpolnischen). Das ist
dasselbe wie die skythischen Scoloti (wie sich die Skythen selbst nannten).
Der Begriff bezeichnete Viehzüchter, für die diese Tiere von besonderem Wert
waren. Das schottisch-russische Forscherduo – Andrew MacEacharn und Anatol
Klyosov – erklärte, dass der Vorfahr der heutigen schottischen
Highlander-Clans ein Mann mit der R1a1-Haplogruppe war, der etwa 5.000 Jahre
alt war. Jahren im russischen Tiefland. Er wäre auch der Vorfahre der
„Schuhmacher“, der Skythen und der meisten heutigen Polen. R1a kam im Paläolithikum,
also zu einer Zeit, als es in der Gegend noch keine Landwirtschaft gab, nach
Großbritannien und Irland und kann mit R1a-M458, einer slawischen Mutation
aus der Corded-Ware-Kultur, in Verbindung gebracht werden. So würden die
Slawen / Skythen Schreib-, Zucht- und Landwirtschaftsfähigkeiten auf die
Inseln bringen. Die diesjährigen Schlussfolgerungen chinesischer Forscher
liefern ein weiteres Argument zugunsten dieser Theorie, da sie Tausende von
Jahren nach diesen Ereignissen feststellen, dass irische und slawische Lexika
sehr ähnlich sind. Lassen Sie uns hinzufügen, dass Irisch die einzige
keltische Sprache war, die in dem zitierten Werk enthalten ist. So hat die
bis heute erhaltene keltische Kultur möglicherweise gemeinsame Quellen mit
dem slawischen Raum und nicht mit afrikanisch-iberischen Einflüssen. |
| |
Die
phonetische Nähe des Polnischen und Ukrainischen zum Kurdischen. Dieser
überraschende Befund könnte mit kurdischer mtDNA zusammenhängen. Ivan Nasidze
und sein Team machten in der Arbeit „MtDNA and Y-chromosome Variation in
Kurdish Groups“ auf die typische kurdische Haplogruppe HV1 aufmerksam, die
aus dieser Region der Welt stammt und nahe an H liegt (45 % bei
zeitgenössischen polnischen Frauen ) und V. Sie gaben an, dass – unter den
Westasiaten – die kurdischen Populationen in mtDNA den europäischen am
ähnlichsten sind. Diese detaillierte Arbeit zeigt eine etwas andere Distanz
zwischen kurdischen Frauen und europäischen Frauen als die Chinesen, aber -
wie ich bereits erwähnt habe - ihre Entwicklung ist genetisch sehr allgemein
(außer R1a - ohne Mutationen, Kladen usw.). |
| |
Die
Slowenen sind den Nordslawen und Norwegern genetisch näher als die Tschechen.
Andererseits scheinen sie dem historischen Kern der baltoslawischen Sprachen
unter den heutigen Slawen sprachlich am nächsten zu sein. |
| |
Die
größten Ähnlichkeiten zwischen slowenischem und vedischem Sanskrit in der
Arbeit „Indo-Aryan and Slavic Affinities“ wurden von Joseph Skulj und Jagdish
C. Sharda festgestellt. Sie präsentierten eine reiche Sammlung von
gemeinsamem Vokabular beider Sprachen. Hier ist ein Fragment ihrer Ergebnisse
– zuerst das polnische Wort, dann das Sanskrit-Wort und schließlich das
slowenische Wort: beleben ajijivat oživeti, Feuer agni ogenj, agnisztha
ogjišče Lagerfeuer, schwimmen apuplavat poplaviti, zupfen askauti
oskubiti, bewegen asuvćuszógtavati, bolećuszógtavati, Mund a
bolećógtavati bhaga sumpf, reich bhagavat reich, angst bhijas bojazen,
flash bhlasate bleščati, bruder bhratri gör, augenbraue bhru stirn,
bhuta biti sein, bhurati buriti kräuseln, bes'ati bežati laufen, braviti
praviti predigen, bodhati buditi erwachen - usw., etc., |
| |
Im
vedischen Sanskrit haben wir die ältesten schriftlichen Formen der Sprache,
die von den gemeinsamen Vorfahren der heutigen Slawen und Hindus verwendet
wurde. Aus Mittel- und/oder Osteuropa verbreiteten ihre Sprecher im 3. und 2.
Jahrtausend v. Chr. die Rede von Irland bis nach Indien. Die Tatsache, dass
es in den westlichen Sprachen der Zweige der Nordslawen (zu denen die
Slowenen gehören sollten - entgegen der akzeptierten Klassifizierung) am
genauesten erhalten wurde, weist auf die wahrscheinlichste Quelle
zeitgenössischer indoslawischer Sprachen hin zeitlich, geographisch und
sprachlich. |
| |
Indem
ein kleines Detail der chinesischen Arbeit in Bezug auf die verwendeten
Genotypen beschuldigt wird, ist dies ein weiterer Beweis dafür, dass sich in
der modernen Wissenschaft das Wissen um die Verbindung menschlicher
Haplogruppen mit Sprachen, die von einzelnen Bevölkerungsgruppen verwendet
werden, auf der ganzen Welt verbreitet hat. Er beweist, dass in dieser
Richtung durchgeführte Analysen die Richtigkeit verschiedener Theorien von
Linguisten und Historikern überprüfen können. |
| |
sagt
Leszczyński |
| |
Wem
die Botschaft in gesprochener Form gefällt, dem empfehle ich einen Vortrag
von Adrian Leszczyński, der den Wissensstand über den Zusammenhang von
Genen mit Sprachen organisiert. Er präsentierte es auf dem 3. Historischen
Festival, das dieses Jahr in Muchów stattfand. Leszczyński erörterte
unter dem Titel "Die Herkunft der Slawen nach genetischer
Forschung" die aktuellen Schlussfolgerungen, die sich aus den
Erkenntnissen der Genetik in Bezug auf die Slawen ergeben. Ich möchte nur darauf
hinweisen, dass ich nicht damit einverstanden bin, nur auf der Grundlage
fossiler Proben zu schließen, weil sie für die Slawen aufgrund des
Verbrennungsritus ein unvollständiges Bild geben. |
| |
Auf
dem Hauptfoto ein Foto aus dem Konto von Adrian Leszczyński aus
Slowenien - der gesamte Fotobericht auf der Website von Czesław
Białczyński. Auf Slovanieukrytahistoriapolski.pl schlagen wir auch
die Eindrücke eines Polen aus der Kommunikation mit der slowenischen Sprache
vor. |
| |
Wenn
Sie möchten - abonnieren Sie unseren Newsletter, der Sie über neue Einträge
in unserem Blog informiert. Es genügt, eine E-Mail mit dem Passwort
NEWSLETTER im Titel zu senden |
| |
|
| |
|
| |
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
|
|